
A business intelligence system is going to require data that can be connected in some way. The easiest way to connect lots of data together is to have it all stored in the same place – your data warehouse. But moving this data into your warehouse is sometimes easier said than done. As a company, it is rare that your data all exists in the same system. It is likely stored across many databases, local files, within third-party vendors, and spread across the entirety of your company’s data infrastructure. Given the size and scale of your company’s data, your data warehouse is typically going to be made up of many hundreds, if not thousands, of different sources. So how can you and your company get this data under the same roof for analysis? You will need to explore and understand the data collection process that enables you to copy your data from its original source and into your BI data warehouse where it can be most effectively leveraged for insight.
Data collection can be done in many ways depending on where your data lives, the technologies you are familiar with or have access to, and what your system requirements are. Though there are many sources of data and ways to acquisition data into your system, the process will ultimately look similar however it is accomplished. Data collection is going to require some form of data movement where you have a source of data and then a target table that lives inside your data warehouse. The data then moves from source to target. This movement from source to target should ideally be engineered in a way that is automated, scalable, maintainable, and repeatable. These data pipelines will tap into your source data, periodically run for extract, and load your copied data within your target tables. From the target tables within your data warehouse, you are then free to continue the BI process to transform, clean, and model your data for analysis.
Data Pipelines
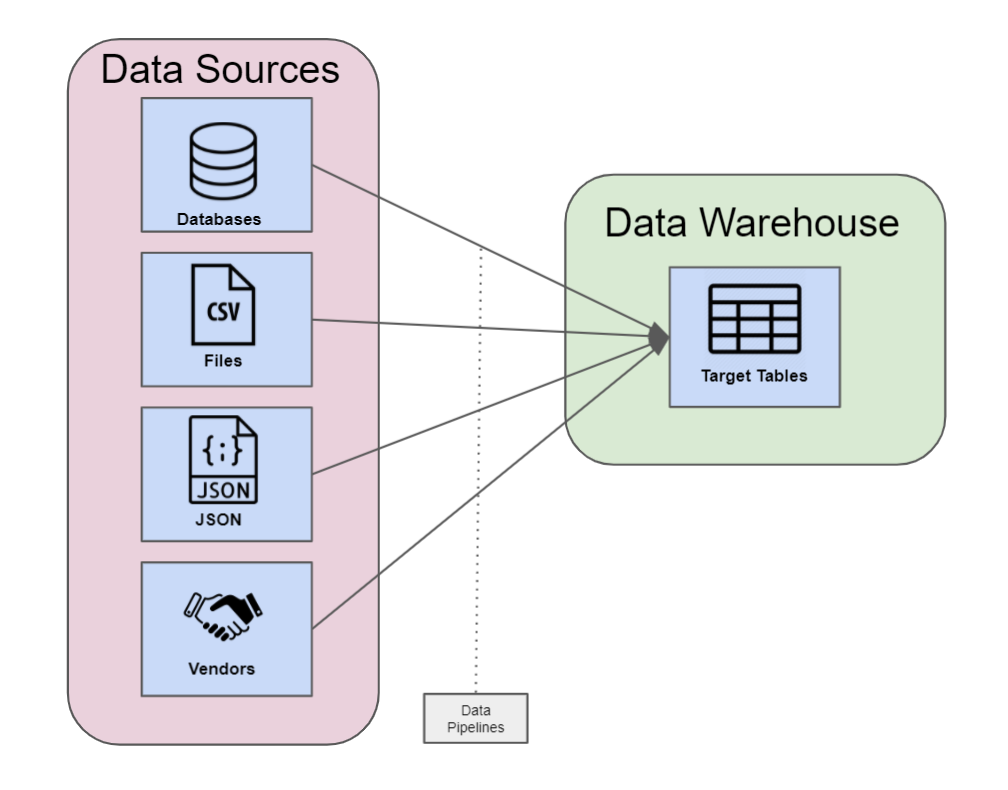
Data Pipeline Considerations:
- Automation: Ideally, your data collection pipelines should be automated so that they require no manual work for processing. When you get to the scale where you have hundreds of pipelines feeding your data warehouse for collection, it quickly becomes difficult to manually process these pipelines in a timely manner. Speaking of scale, it is reasonable to expect your company data to grow larger with time. Because this growth is inevitable, you will need to make sure you account for and anticipate the growth of your source data.
- Scalability: This growth is why scalable pipelines should be the norm for how you develop your data collection solutions. A failure to develop and account for scalability can lead to bottlenecks with unreasonable load times that slow or halt your entire system. Even with the scalable solutions, your data collection pipelines can sometimes bottleneck or fail. Therefore, it is important to make sure they are maintainable.
- Maintainability: Maintainable pipelines should have logging in place to monitor health and performance that enables you to easily track down where slowdowns or failures are occurring in the system. This will allow you to precisely home into issues to make efficiency improvements and track down bugs. Your data pipelines should also account for any dependencies so that data is loaded in the right order where order might be necessary.
- Repeatability: Finally, repeatability is the key to an effective solution. The stakeholders that will utilize your BI solution need fresh data for synchronized decision making. Hosting your pipelines for periodic processing will help stakeholders to see their business processes in near real time.
Because your source data can vary in size, the way in which you copy fresh data into the target table will vary as well. You can explore options that will either fully load or incrementally load this data.
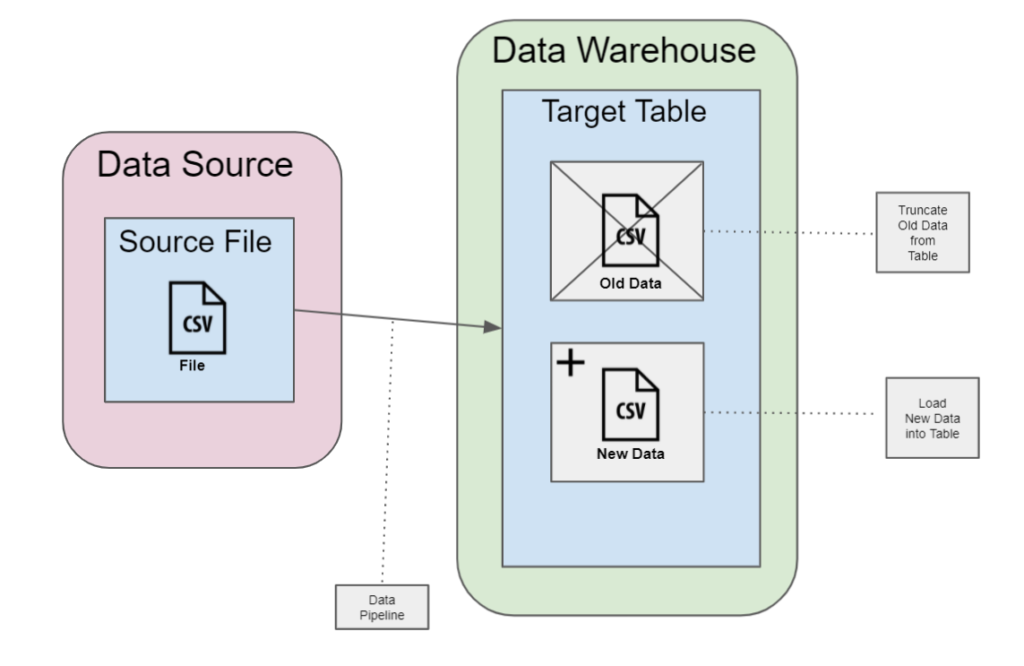
Full Load: In a “full load” process you will delete or truncate the data from your target and reload the source completely. The reason for a full load is that it is sometimes faster to load all your data from scratch than it is to only load the most recent changes or differences that have occurred since your last load.
Full Load
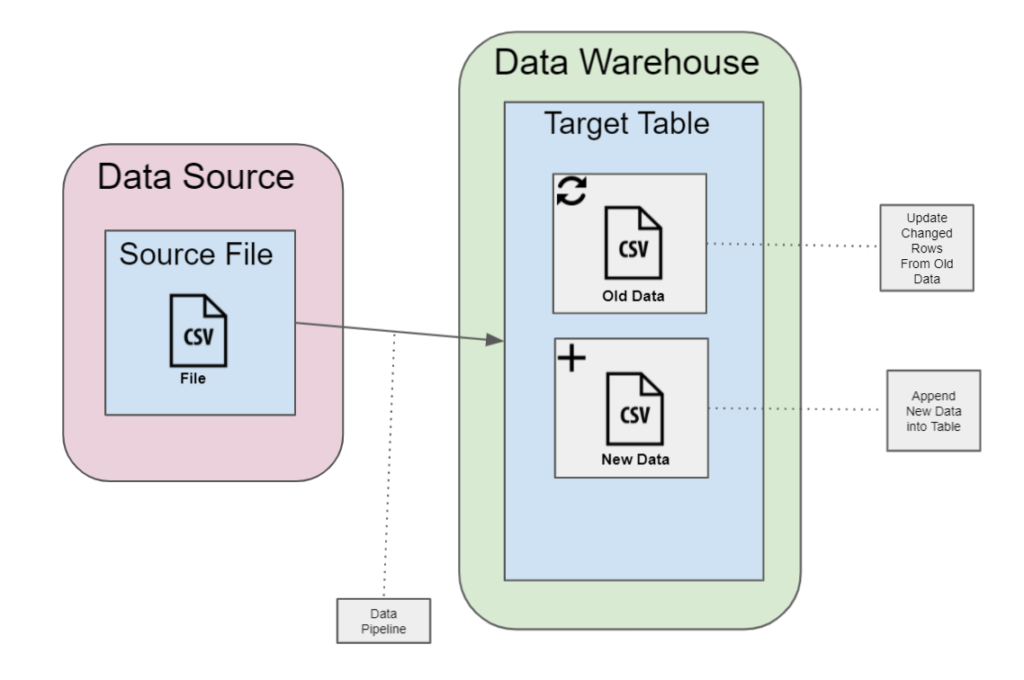
Incremental Load: Other times, it may be faster to run an “incremental load” of your data. This incremental load will not wipe your target table like a full load but will instead only load the new or changed data. If your source data only collects new transactions but does not change previous data, it is enough to only copy the rows that have been written into your source since you last loaded. But if instead your source table can change or update previous rows of data, you will want to develop a solution that checks for these changes and updates these changed rows within your target.
Incremental Load
You will want to determine whether a full load or incremental load is right for your specific data collection pipeline by understanding how the data in your source will change, how the size of the source may be expected to grow over time, and by testing the time difference between load types.
In an advanced BI solution, a company can expect to home thousands of data collection pipelines that feed their source data into their data warehouse. These solutions are going to ultimately require the dedicated support of data engineers to maintain and develop. Data engineers at this size will need to determine the technologies they use for their data collection pipelines. These pipelines can be coded through custom solutions or outsourced to tools that help streamline the process and require less manual engineering. Finding the best solution for your company will take time and experience, but for those just getting started, the most important thing is just getting the data into your data warehouse. From here you will be able to model and visualize your data to see how powerful a growing BI solution will inevitably become for your company. With BI in hand, your company’s decision makers will refuse to downgrade to a less intelligent time before BI.


